
第一步:你得先进行页面的获取吧,这时候使用到curl命令
我要获取的内容:
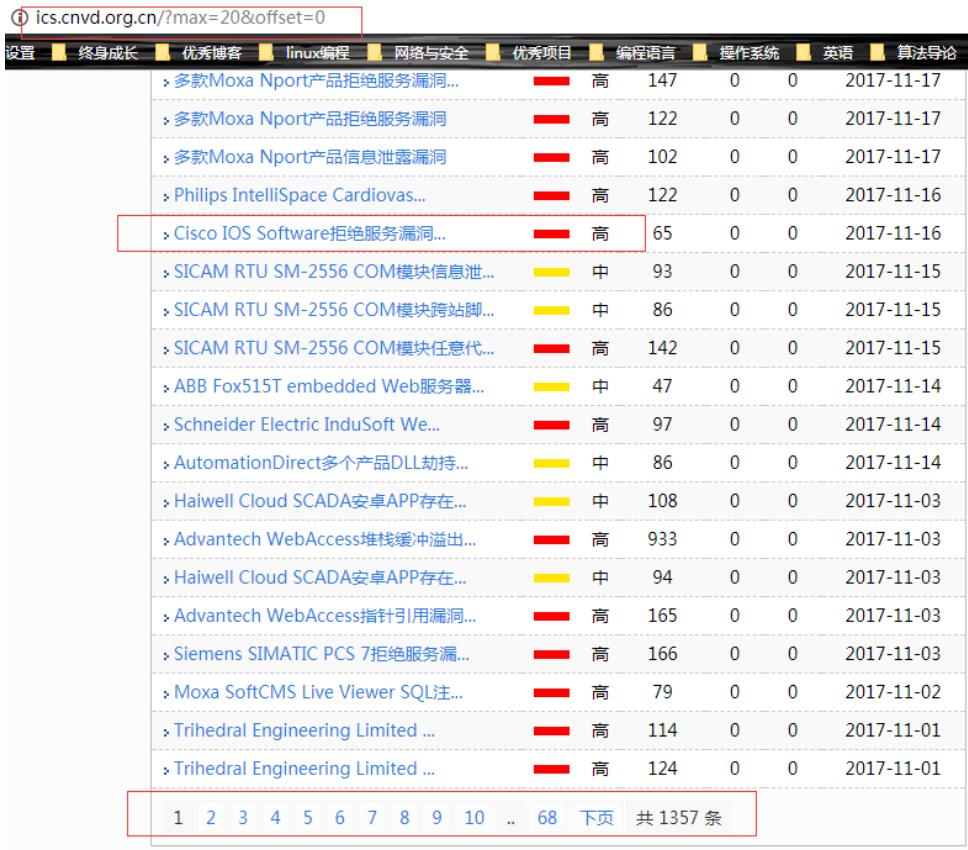
单个页面的下载:
curl -o 0 http://ics.cnvd.org.cn/?max=20&offset=0
第二步,对每个单页面中的连接进行抓取:
此时单个连接如下所示:
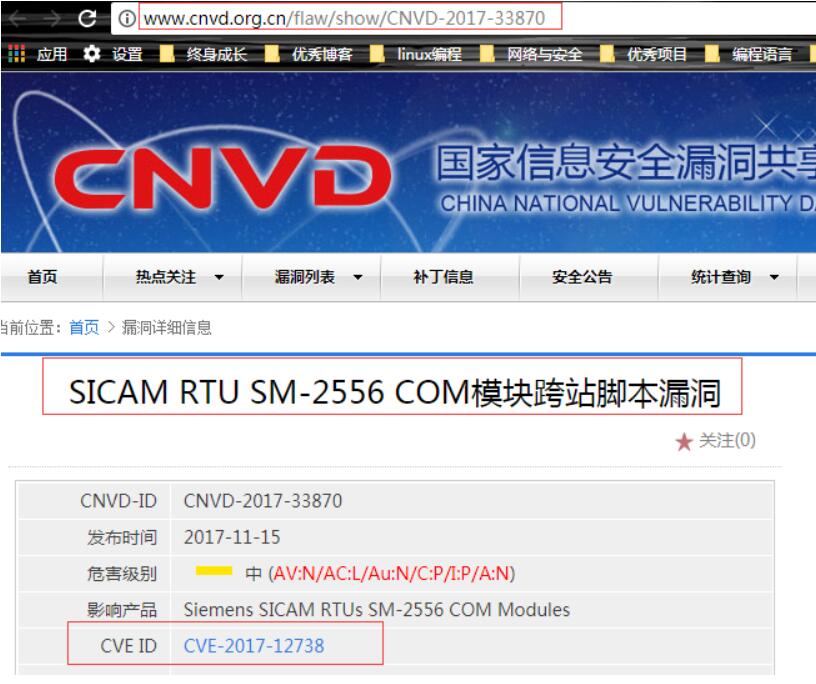
单个页面的下载:
curl -o 0 http://ics.cnvd.org.cn/?max=20&offset=0
第二步,对每个单页面中的连接进行抓取:
此时单个连接如下所示:
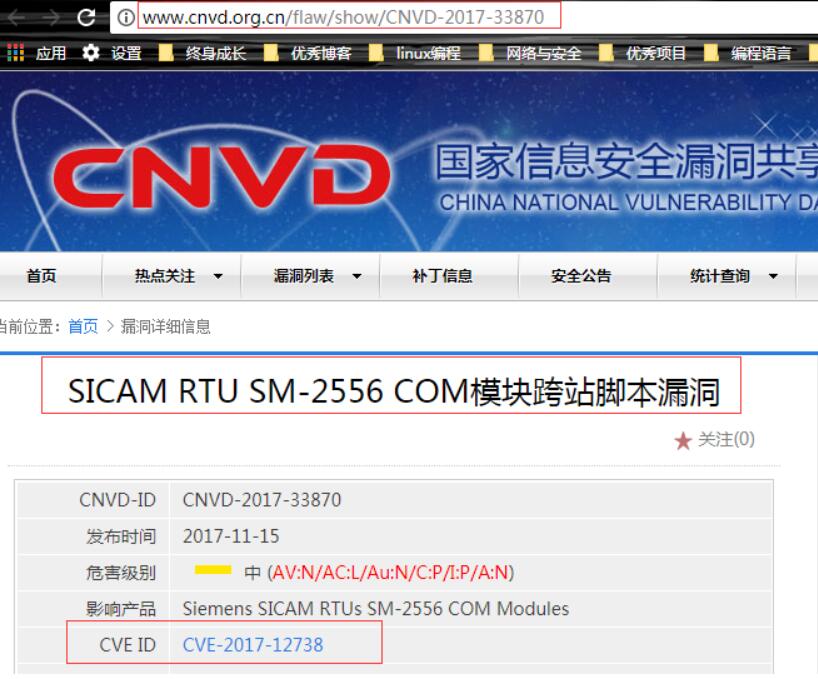
grep -o 'http://www.cnvd.org.cn/flaw/show/CNVD[0-9\-]*'; 0
第三步:以上简单样例实现了,就进行获取68页的所有内容:

这是第二页的url
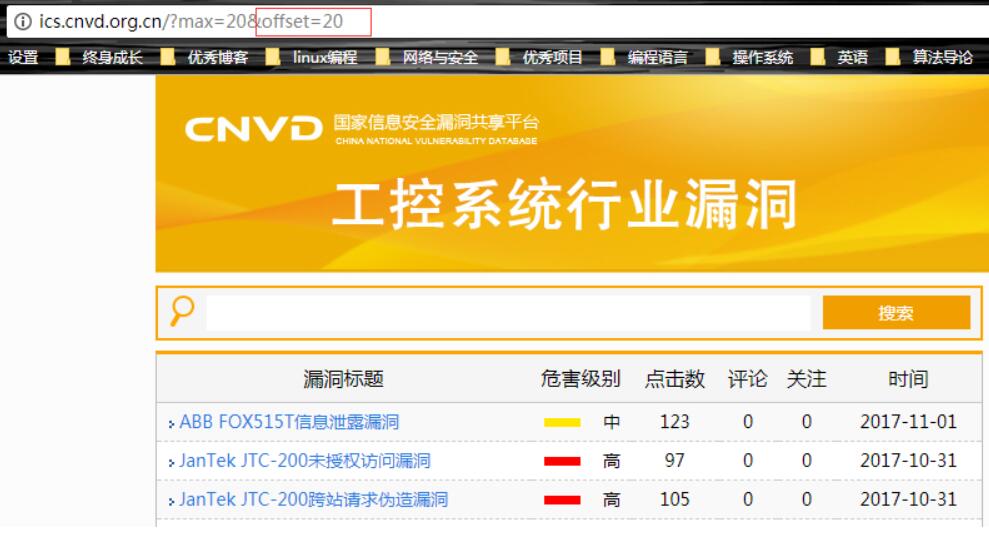
for n in `seq 0 20 1340`; do curl -o $n http://ics.cnvd.org.cn/?max=20&offset=$n; done
执行之后,获取到的所有url,如下所示:

第四步:将所有的网页中的信息,选项每个内部连接,保存到一个文件中:
grep -o 'http://www.cnvd.org.cn/flaw/show/CNVD[0-9\-]*'; * > url.txt
最后文件内容如下所示:
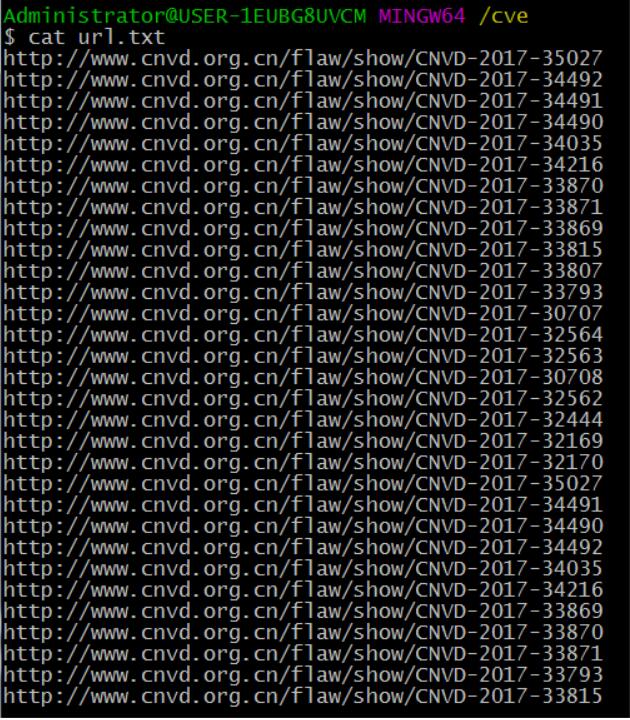
第五步:将url中的所有内容分析到需要内容,进行合并,例如
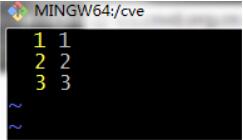
1.txt
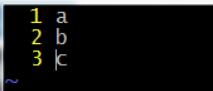
a.txt
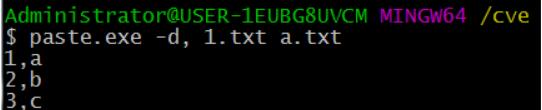
合并:
paste.exe -d, 1.txt a.txt
转载请注明:HunterYuan的博客 » 用Shell实现简单爬虫




